
Better performance in batch imports to SQL Server using BizTalk
During my years of BizTalk development I’ve been warned of a couple of scenarios that the product wouldn’t handle very well. Yesterday another of those scenarios turned out to kind of false and, if done right, not really a problem at all.
The scenario I’m talking about is a batch import of data to SQL Server using the SQL adapter. In my case the data is received as a flat text file containing a large number of rows. These rows should the be places inside a database table as one table-row per row in the flat file.
The common way of dealing with batch incoming data like this is to split (aka disassemble) it in the receive port using the Flat File Disassembler pipeline component (for a good example - look here). Disassembling the data when receiving it is usually good practice to avoid running into OutOfMemoryException when dealing with big messages.
Sometimes the requirements also forces one into reading each row to a separate message to be able to route and handle each messages in a unique way depending of it’s content. If that so - this is a not a good post for you. In this post I’ll discuss the scenario were all the data just needs to go as fast as possible from the text file into a single database table. No orchestration or anything, just a simple batch import.
So, what’s The problem with the batch import scenario?
When I implemented similar batch import scenarios in the past I tried to practice good practice and split the data into separate files that I then filtered to the SQL adapter send port, one by one.
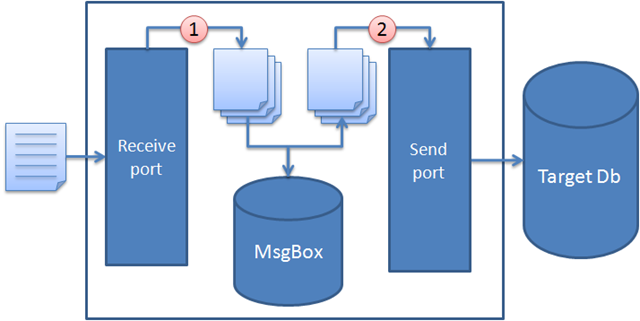
- The received flat file files has been split into thousands of small little message that one by one are sent to the SQL adapter send port.
- The SQL adapter then parses each message into a SQL script that executes a store procedure and the message is finally inserted to the target database.
“So what’s the problem?” you then ask? It’s slow! It’s very slow! Each message gets stored a couple of times in the BizTalk database and each message is sent inside it’s own DTC transaction against the target database. And all this adds up …
And after reading this this interview by Richard Seroter with Alan Smith I also felt I was the only one having the problem either …
There are quite a few people asking about using BizTalk for heavy database integration, taking flat files, inserting the data in databases and processing it. SQL Server Integration Services (SSIS) does a much better job than BizTalk at this, and is worth looking at in those scenarios. BizTalk still has its uses for that type of work, but is limited be performance. The worst case I saw was a client who had a daily batch that took 36 hours to process using BizTalk, and about 15 minutes using SSIS. On another project I worked on they had used BizTalk for all the message based integration, and SSIS for the data batching, and it worked really well. > >
Note: As I’ll described later in this post my import scenario went from something like 3-4 hours to 2 minutes (importing 10 MB). Alan talks about a 36 hours (!) import. I don’t know anything more about the scenario he mentions and it might not even be solved using the technique discussed below. Hopefully Alan might comment on the post and give us more details. ;)
How can we get better performing imports using BizTalk?
As the import scenario we described doesn’t involve any orchestration but is a pure messaging scenario and we do all the transformation on the ports we don’t really have to worry about _OutOfMemoeyExceptions _even though the message is quite big.
**Large message transformation.** In previous versions of BizTalk Server, mapping of documents always occurred in-memory. While in-memory mapping provides the best performance, it can quickly consume resources when large documents are mapped. In BizTalk Server 2006, large messages will be mapped by the new large message transformation engine, which buffers message data to the file system, keeping the memory consumption flat. ([Source](http://www.microsoft.com/technet/prodtechnol/biztalk/2006/evaluate/overview/default.mspx)) > >
Another reason for splitting the message was for it to work with the SQL adapter. When setting up the SQL adapter to work with a store procedure the adapter expects a message that looks something like the below.
<ns0:ImportDataSP_Request xmlns:ns0="http://FastSqlServerBatchImport.Schemas.SQL_ImportDataSP">
<ImportData Name="Name 1" Value="1"></ImportData>
</ns0:ImportDataSP_Request>
This tells us that the store procedure called is “ImportData” with “Name 1” as the value for the “Name” parameter and “1” as the value for the parameter called “Value” in the stored procedure. So each little separate message would get mapped on the send port into something like this.
What I however didn’t know until I read this post was that the message I send to the SQL adapter port just as well could look like this!
<ns0:ImportDataSP_Request xmlns:ns0="http://FastSqlServerBatchImport.Schemas.SQL_ImportDataSP">
<!-- TWO rows!!! -->
<ImportData Name="Name 1" Value="1"></ImportData>
<ImportData Name="Name 2" Value="2"></ImportData>
</ns0:ImportDataSP_Request>
So basically we can have as many store procedure calls as we want in one single file that then can send to the SQL adapter send port!
Eureka! **__This means that we don’t have to split the incoming file! We can keep it as one big single file and just transform it to a huge file containing separate nodes that we send to the SQL Adapter send port! The SQL adapter will then parse this into separate store procedure calls for us.**
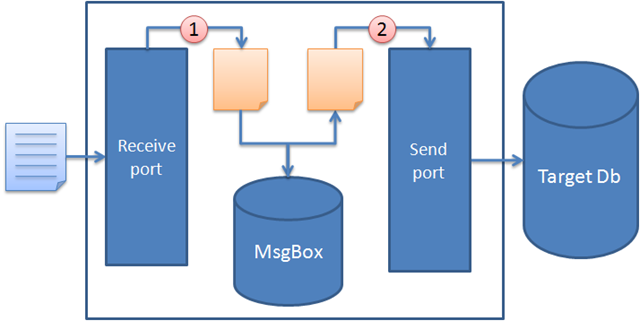 __
__
Is it really any faster?
As the technique above drastically reduced the amount of database communication needed I knew it’d be much faster. Some initial testing shows that an import of a file containing somewhere around 55 000 rows (about 10 MB) into our article database went from 3-4 hours to under two minutes!
See for yourself!
In this sample solution I have a text file containing 2 600 rows. I’ve then created two separate projects in a solutions. One that splits the messages into separate messages (called “SlowImport”) and one that just transforms it and send it as one message to the send port (called “FastImport”). One takes 1:50 minutes and 2 seconds on my development machine … I won’t tell you which one is the faster one …
Test it for yourself and let me know what you think.